
HashMap in java
Let's start with basics, why we need hashmap. Let's assume we want to insert data that is in form of key-value.
By insert, I mean put which is actual method name. Since, we put our key-value data. We want some way to
search (get is actual method name) this data and if need arises, we also want to
delete (remove is actual method name) this data.
These basic operations are
- put
- get
- remove
In java, HashMap is a class that implements the Map interface. And the methods that I have written above are
most popular (frequently used) out of
list of the methods map interface provides.
If you have visited the link, Map interface provides a long list of methods. I have also used getOrDefault method multiple times.
Still, the question remains unanswered, why we need it. we can probably use ArrayList
(maybe store custom key-value instance) ? We use hashmap because it is performant. It has O(1) average time for
insertion, searching and deletion.
Before I give you the HashMap code example. Let's go back and think how can we make such a data structure that
that provides O(1) operation guarantee. We assumed our keys are numerical (or hashcode of instance which is
always numerical) and the value can be any object.
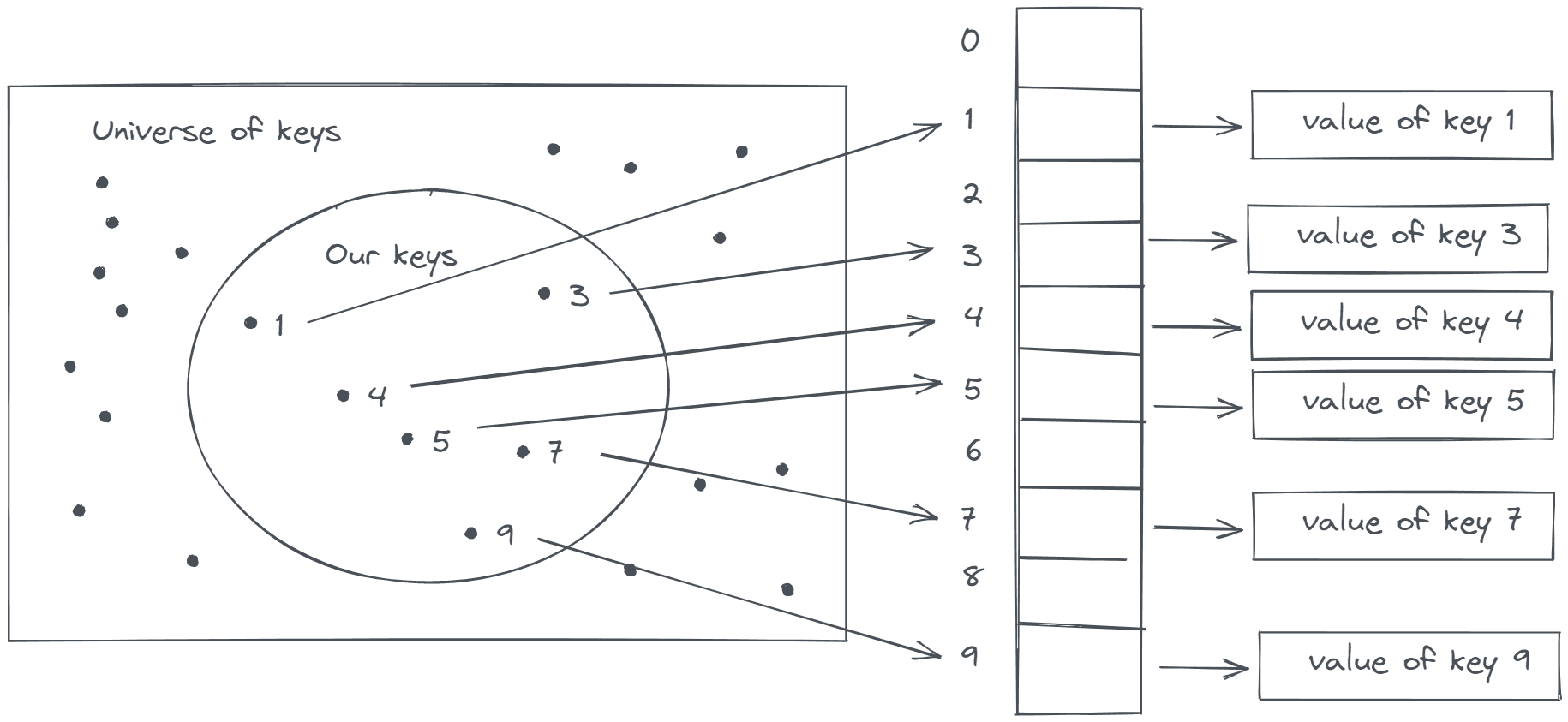
Above figure is an example of Direct Addressing, in which keys are mapped one-to-one to the index of the array.
This, structure will ensure that our operations like put, get and delete will take O(1) time only. But there is a major
problem with this, imagine your key set are 1, 10, 1000, 10000 even though our key set has only four keys but the
table size required to map them are 10000 in which most of the space are wasted.
What can we do to improve ? Such that we should be able to create a small array say size of 10 and map these keys
to it. Now, note what should know before-hand Approximately how many keys should we require to
map so that we create an array of size greater that this. Now, to map our numerical keys to index of arrays, we
perform hashing on the keys.
On this page
- What is hashing ?
- What is hash function ?
- Collision and how hashmap manages it
- Node and TreeNode
- Importance of immutable keys
- Performance of hashmap
- Demonstrating basic hashmap operations
- Conclusion
What is hashing ?
Hashing is a process of converting a value to another value. So, in our case we want to convert the key (which can range from 1 to pretty large no (technically it can be negative also)) to index of the array (which is relatively small).


What is hash function ?
Well it's pretty obvious from above figure that role of hash function is to receive some value and convert it into some other value. One mandatory feature of hash function is, it should be deterministic. It means for the given input (eg. key) it should produce the same output (eg. index).
What about hash function that produces the same result for every input, it would be the worst hash function. So, a good hash function should produce output (eg. index) that is uniformly distributed.
Division method
We can map our key k to one of the index of array (size of array = m) by taking remainder
of k divided by m.
h(k) = k mod m
For uniform hashing, we can take m as prime no. which is not too close to exact power of 2.
Hash function in java
In java, our key is always object. And there no single method that takes the key and convert it into the index of our
array (actual declaration of this array - transient Node<K,V>[] table; ). In OpenJDK code, first key is passed
to hash function, it returns some number. Then if n is size of the array, index is calculated by
(n - 1) & code_returned_by_hash_method it ensure that the returned value is less than n.
Here is code of hash method straight from OpenJDK.
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Collision and how hashmap manages it
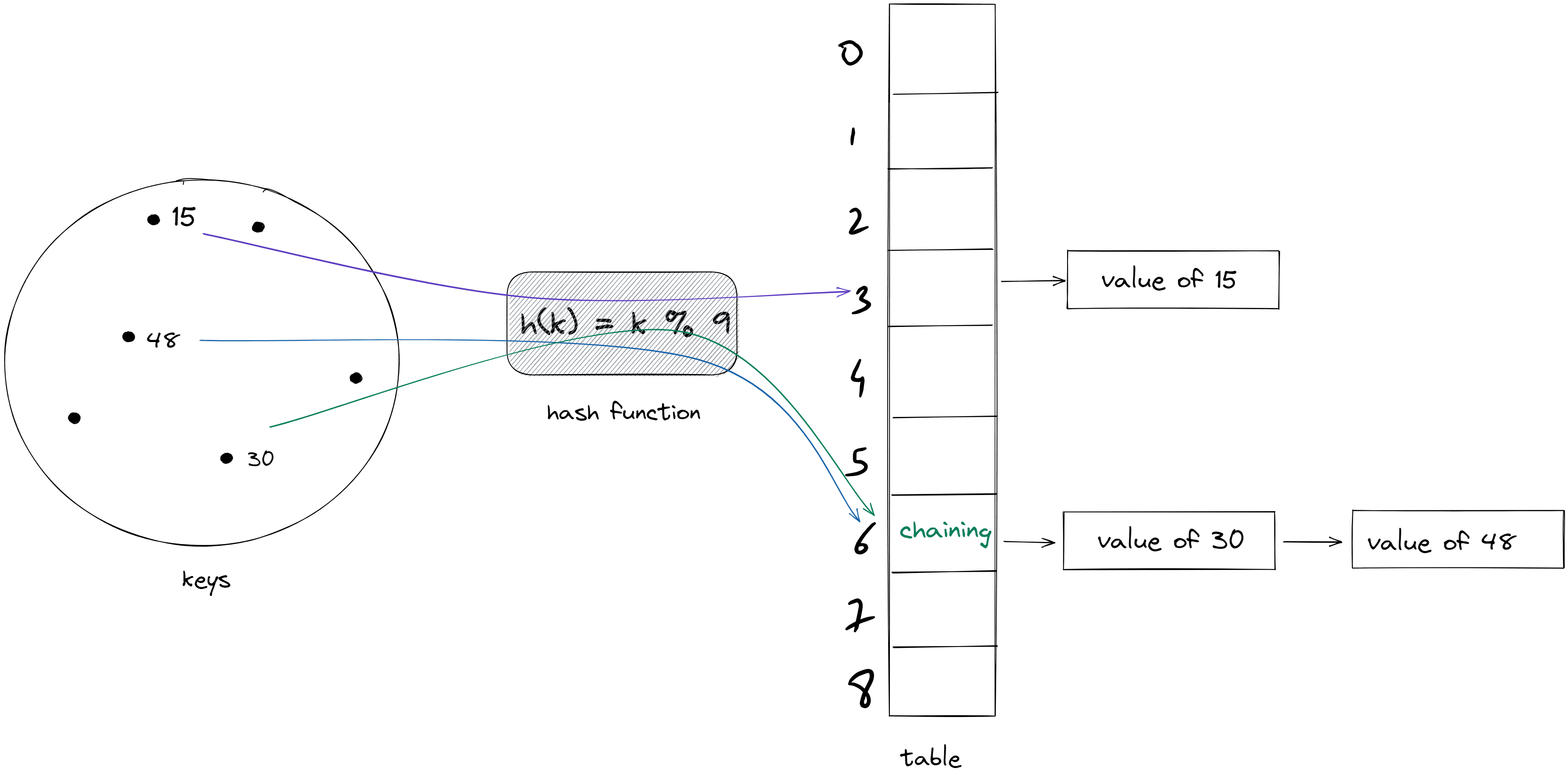
It is also possible that for two or more keys, hash function returns the same index. When that happens it is called a Collision.
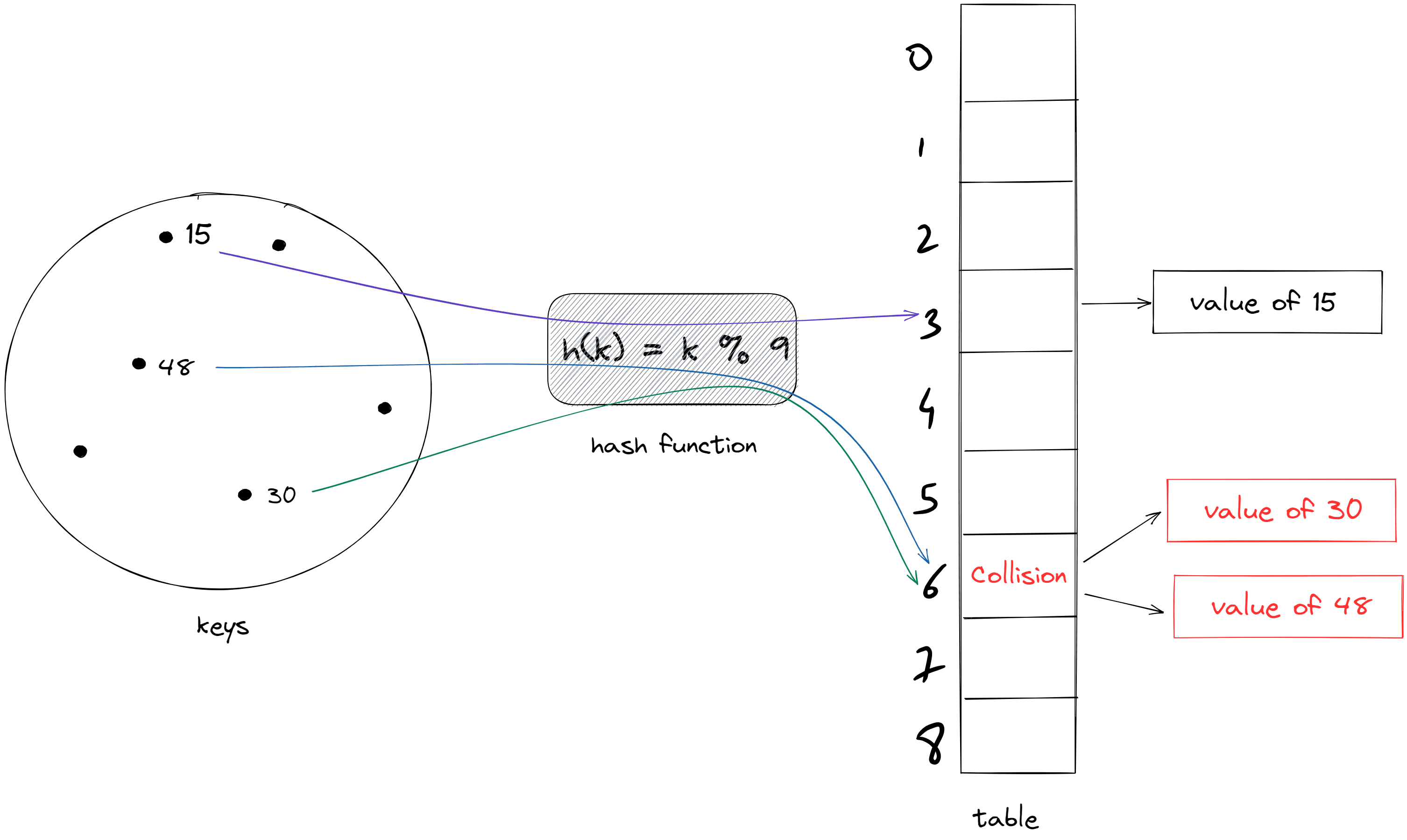
In above figure, hash function (h(k) = k % 9) is taken for illustrating concept. Actually, its functionality is divided into two parts as explained here.
In above figure, it is clear that it is not possible for array at index 6 to store the values of both the key 30 and 48. So, we need a way to manage it.
Collision resolution
The way java's hashmap manage the collision is by chaining. In this, our table stores the reference of LinkedList.
And if there is collision while adding the element in the table at particular index. The element is actually added
to the linked list. And at the time of searching, element is searched in a linked list. During search equals method
is used to compare the searched key.
In worst case, all our element can be mapped to same index (eg. due to poor hashcode implementation)
and the time to search would be O(n). So, for scenario like this if the length of linked list exceed some threshold
(static final int TREEIFY_THRESHOLD = 8;). The linked list get converted to red black tree. Thus, bringing the worst case
time for searching to O(log n). This tree will also be converted back to linked list if no. of nodes in tree are within
some threshold (static final int UNTREEIFY_THRESHOLD = 6;).
Node and TreeNode
Node and TreeNode are the static inner classes of the HashMap class. Node is used by default for every entry. But if Tree is used Node get converted to TreeNode.
Inside HashMap.java
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// constructor, getter and setter, equals ...
}
We can see, Node class implement Map.Entry interface.
So, while using hashmap, we usually use this Map.Entry interface and
not Node class.
Inside HashMap.java
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
// other methods ...
}
Inside LinkedHashMap.java
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
We can see from above two code snippets, HashMap.Node is superclass of HashMap.TreeNode class. Hence, we can still refer
hashmap entry instances as Map.Entry and should not be concerned with internals where map can use Node or TreeNode.
Importance of immutable keys
Imagine you have put some key value pair in the hashmap, and later when you try to get this value by key - it was not found in the map. Is it possible ? Yes if we are not careful. We know that key are mapped to table's index based on hashcode. If we have provided own custom implementation of hashcode such that it depends upon the instance fields of the class. There is possibility that when we search item in map, it was not found.
If the hashcode of the key while inserting the element and then during searching are different, then map has no way to find that key. Here, I am saying hash code are different. But how can the hashcode of same instance be different. Well in last paragraph I have told you that hashcode usually depends on instance fields. So, if you have modified the data of fields, then there is possibility of different hashcode.
Here is code showing the same.
import java.util.HashMap;
import java.util.Map;
public class MutableClass {
int value;
MutableClass(int value) {
this.value = value;
}
void setValue(int value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MutableClass that = (MutableClass) o;
if (value != that.value) return false;
return true;
}
@Override
public int hashCode() {
return value;
}
}
class Demo {
public static void main(String[] args) {
MutableClass firstKey = new MutableClass(1);
MutableClass secondKey = new MutableClass(2);
Map<MutableClass, String> map = new HashMap<>();
map.put(firstKey, "One");
map.put(secondKey, "Two");
firstKey.setValue(11);
System.out.println(map.get(firstKey));
System.out.println(map.get(secondKey));
}
}
Output
null
Two
To, avoid such cases, it is recommended to use immutable instances as keys. So, we don't encounter such problems.
If we don't override hashcode implementation then java automatically generate hashcode and jvm ensures that it returns the same value if it was called more than once.
Performance of hashmap
Performance of the hash table is affected by initial capacity and load factor. We know when a key is added to hashmap, its index is mapped to a table. The size of this table is called its capacity. And when our hash table is filled a certain percent, size of the table is approximately doubled and keys are rehashed. This percentage when the table size is increased is called load factor.
Default load factor is 0.75, it provides and good tradeoff between time and space cost. We can increase or decrease
load factor. If we increase the load factor, it will decrease space overhead at cost of lookup time.
Default initial capacity is 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
Demonstrating basic hashmap operations
Declaring the HashMap
Map<String, Integer> map = new HashMap<>();
Look at the type of key and value. In above example, my key type is String and value type is Integer. You cannot add primitive types as Key or Value.
Adding element in hashmap using put
map.put("one", 1);
map.put("two", 2);
As we can see, put method accept two arguments, first one accept key and second one its value.
Complete example with main method:
class DemoHashMap {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
}
}
Getting the value on for the given key
You can use get method as told earlier.
class DemoHashMap {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
int oneValue = map.get("one");
System.out.println(oneValue);
}
}
Removing the key value pair
We can use remove method and passing key as its argument.
class DemoHashMap {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
map.remove("two");
System.out.println(map);
}
}
Iterating all key value pair
We can use entrySet method to iterate over all elements.
class DemoHashMap {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
for (Map.Entry<String, Integer> entry: map.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
System.out.println("key = " + key + ", value = " + value);
}
}
}
Check does the map contains a particular key
We can check for presence of the key using containsKey method
class DemoHashMap {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
boolean isOneKeyPresent = map.containsKey("one");
boolean isThreeKeyPresent = map.containsKey("three");
System.out.println("isOneKeyPresent: " + isOneKeyPresent);
System.out.println("isThreeKeyPresent: " + isThreeKeyPresent);
}
}
Its output:
isOneKeyPresent: true
isThreeKeyPresent: false
Conclusion
In this post, I have explained the internal working of hashmap with examples, why we need hashmap and what type of operations it performs. Then, how does hashing occurs (both general and in java). What happens when collision occurs and its resolution. Performance of hashmap.
If you liked this article, consider following me on twitter where I will be announcing for new posts.